





⚽ 激情绿茵 • 全球盛宴 • 一触即发 ⚽
沉浸式观赛体验,感受世界杯激情
全方位满足您的世界杯观赛与互动需求

{文案信息库}

{文案信息库}

{文案信息库}
浏览平台精彩瞬间
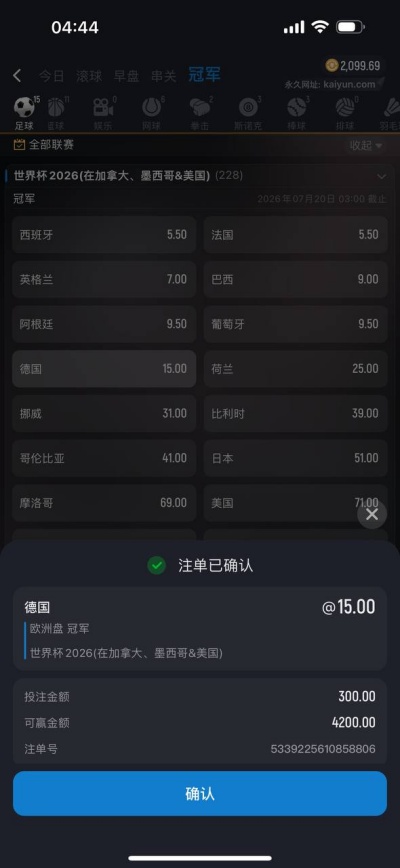
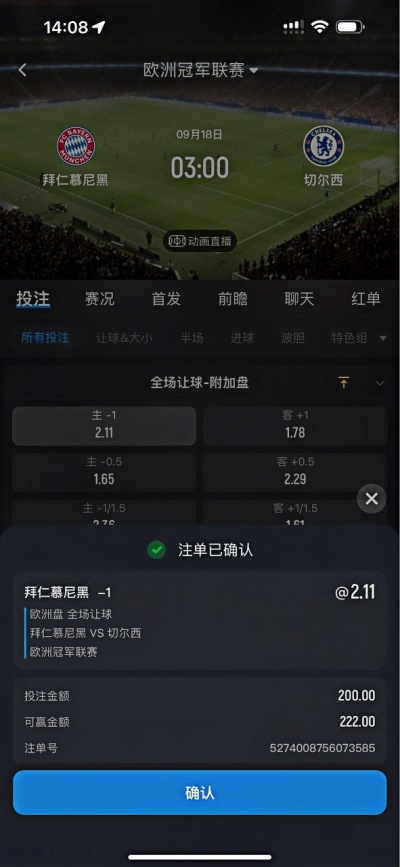
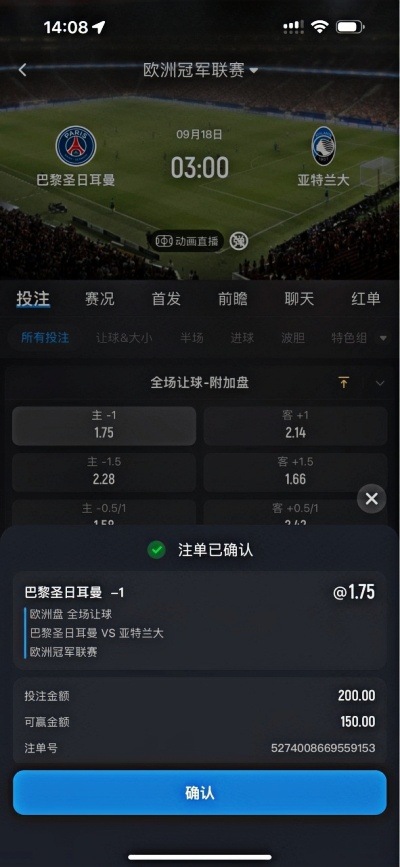






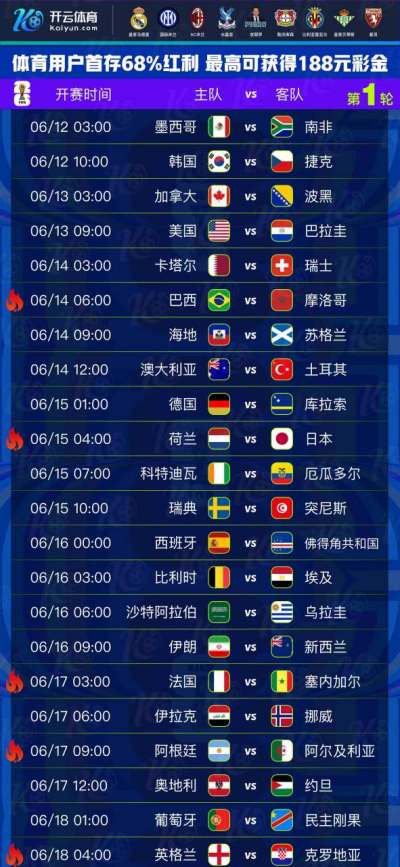


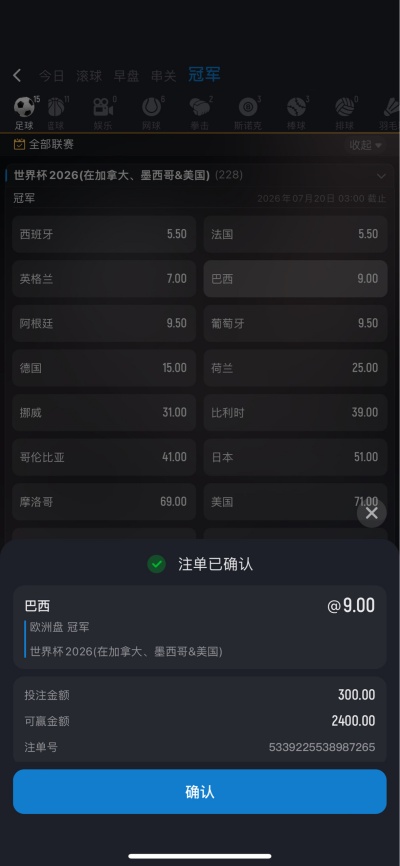
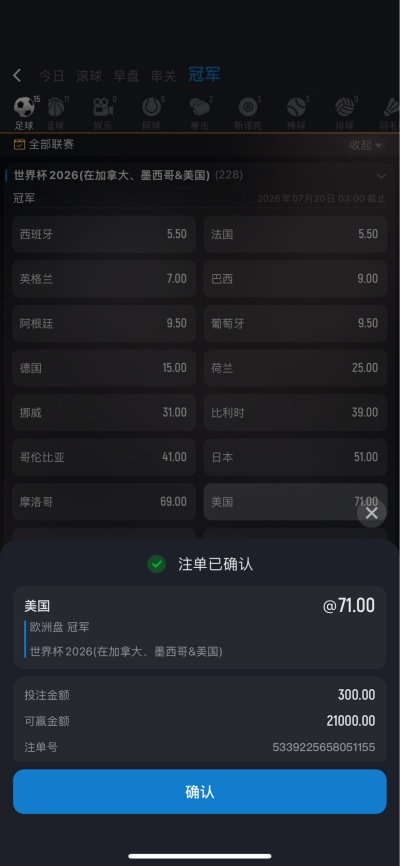
专业铸就品质,信赖成就未来
全天候在线客服,随时随地解决您的疑问
顶级加密技术保障您的账户与资金安全
毫秒级响应速度,操作流畅不卡顿
新用户专享福利,优惠活动不断升级
来自全球用户的信任与认可

Description(描述)

Description(描述)

Description(描述)

Description(描述)

Description(描述)